4. If your system is configured to support 10 GbE cluster interconnect and data connections on 40 GbE NICs
or onboard ports, convert these ports to 10 GbE connections by using the nicadmin convert command from
Maintenance mode.
Be sure to exit Maintenance mode after completing the conversion.
5. Return the controller to normal operation:
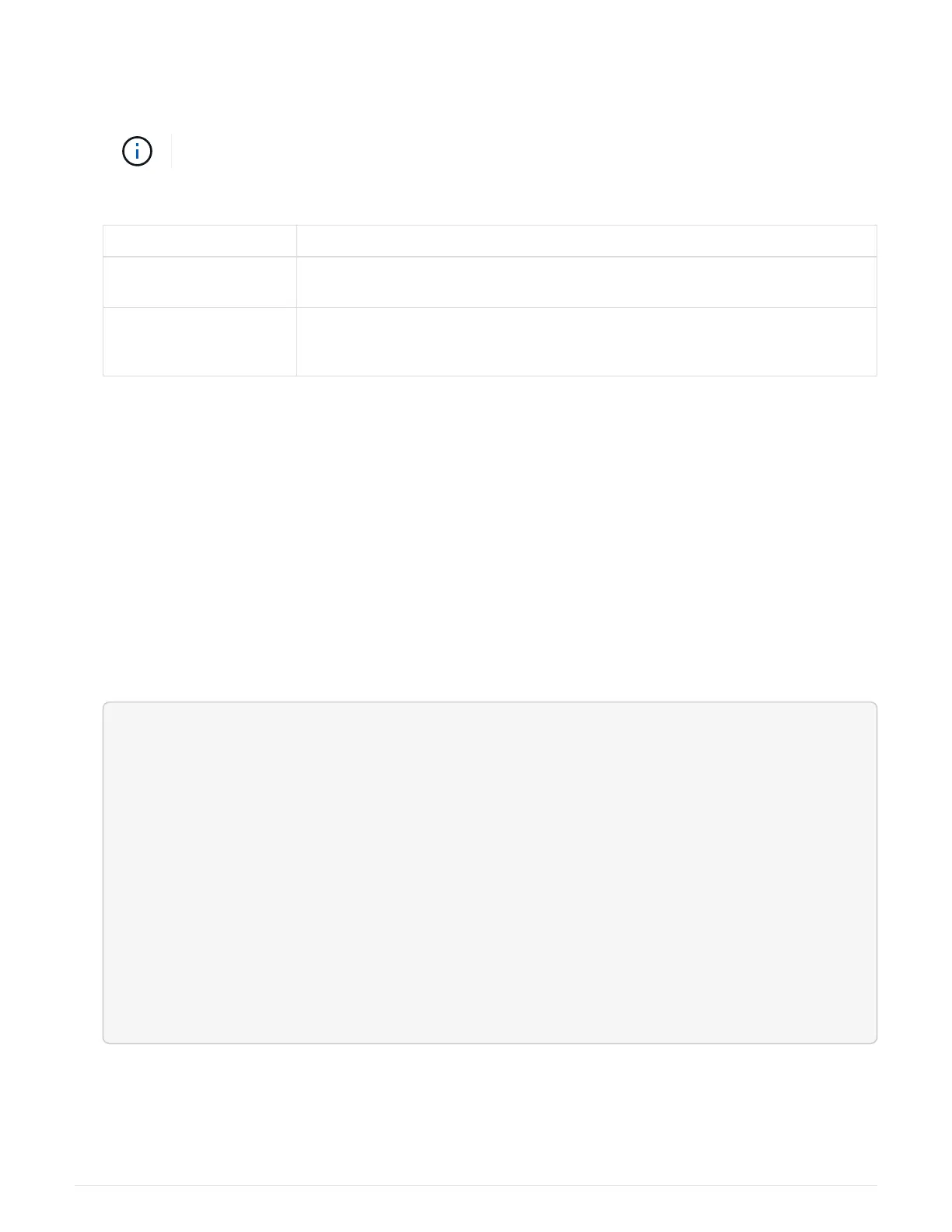
If your system is in… Issue this command from the partner’s console…
An HA pair
storage failover giveback -ofnode impaired_node_name
A two-node MetroCluster
configuration
Proceed to the next step. The MetroCluster switchback procedure is done in
the next task in the replacement process.
6.
If automatic giveback was disabled, reenable it:
storage failover modify -node local -auto
-giveback true
Step 5 (two-node MetroCluster only): Switch back aggregate
After you have completed the FRU replacement in a two-node MetroCluster configuration, you can perform the
MetroCluster switchback operation. This returns the configuration to its normal operating state, with the sync-
source storage virtual machines (SVMs) on the formerly impaired site now active and serving data from the
local disk pools.
This task only applies to two-node MetroCluster configurations.
Steps
1.
Verify that all nodes are in the
enabled state: metrocluster node show
cluster_B::> metrocluster node show
DR Configuration DR
Group Cluster Node State Mirroring Mode
----- ------- -------------- -------------- ---------
--------------------
1 cluster_A
Ê controller_A_1 configured enabled heal roots
completed
Ê cluster_B
Ê controller_B_1 configured enabled waiting for
switchback recovery
2 entries were displayed.
2.
Verify that resynchronization is complete on all SVMs: metrocluster vserver show
3. Verify that any automatic LIF migrations being performed by the healing operations were completed
successfully: metrocluster check lif show
396