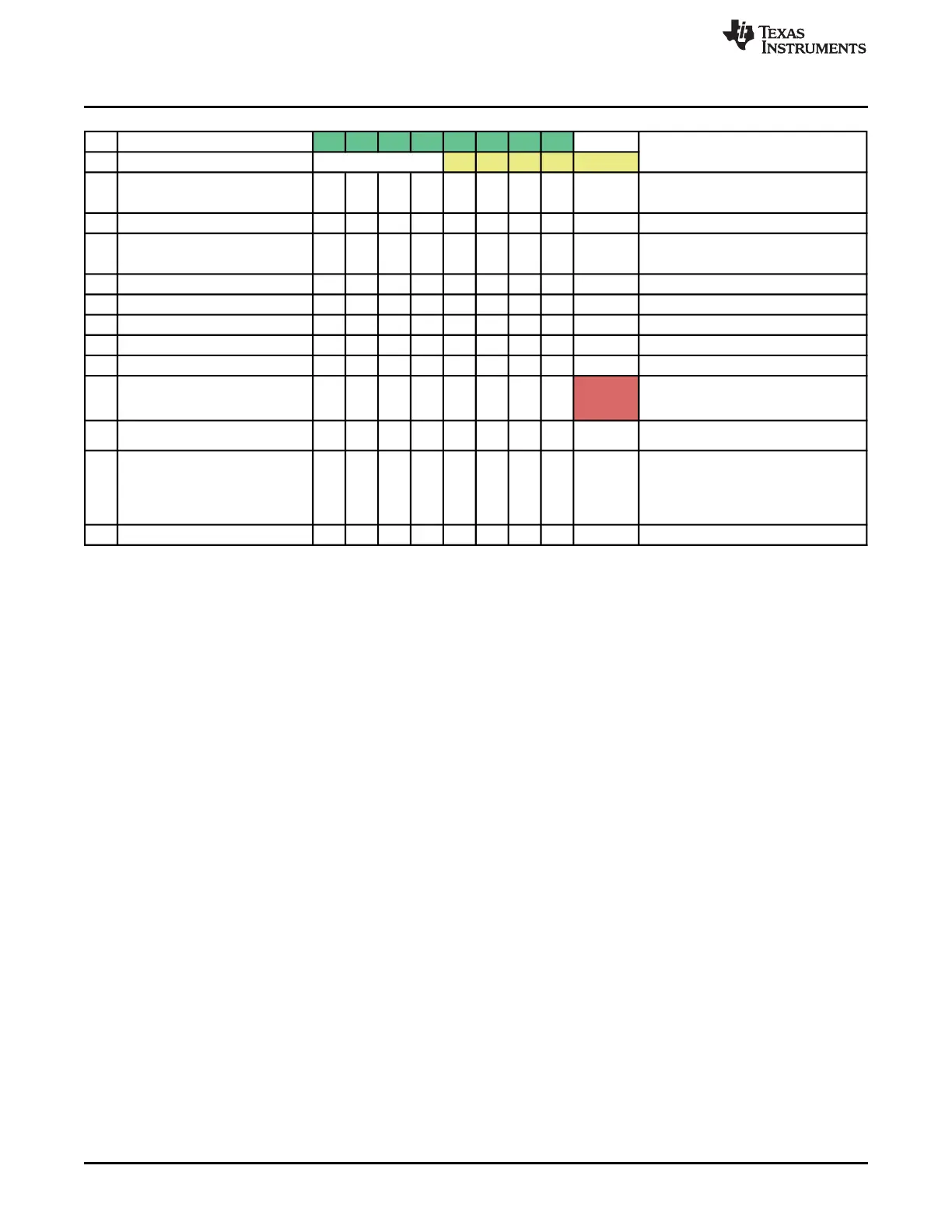
Instruction F1 F2 D1 D2 R1 R2 E W
R1 R2 E1 E2 E3
MPYF32 R6H, R5H, R0H
|| MOV32 *XAR7++, R4H
I2 F32TOUI16R R3H, R4H I2 I1
ADDF32 R3H, R2H, R0H
|| MOV32 *--SP, R2H
I4 NOP I4 I3 I2 I1
I5 MOV32 @XAR3, R6H I5 I4 I3 I2 I1
I5 I4 I3 I2 I1
I5 I4 I3 I2 I1
I5 I4 I3 I2 I1
I5 I4 I3 I2
I1
(STALL)
Due to one extra NOP, I5 does not
reach R2 when I1 enters E3; thus,
forwarding is not needed.
I5 I4 I3 I2 I1
There is no change due to the
stall in the previous cycle.
I5 I4 I3 I2
I1 moves out of E3 and I5 moves to
R2. R6H has the result of R5H*R0H
and is read by I5. There is no
need to forward the result in this
case.
I5 I4 I3
I3 I3 I2 I1
Comments
FPU pipeline-->
I1 I1
Usage Notes and Known Design Exceptions to Functional Specifications
www.ti.com
28
SPRZ412K–December 2013–Revised February 2020
Submit Documentation Feedback
Copyright © 2013–2020, Texas Instruments Incorporated
TMS320F2837xD Dual-Core MCUs Silicon Revisions C, B, A, 0
Figure 6. Pipeline Diagram With Workaround in Place
 Loading...
Loading...









