The Fast Path mechanism is a solution to this problem. In addition to Fast Path detecting full
connectivity loss, as described in the first example, Fast Path can also detect when a server’s
teamed ports have different maximum bandwidth paths to the Core Switch (root switch). By
examining the path cost information contained in Spanning Tree BPDU frames reported by
directly attached switches, a team can detect which switch is the best one to use for the team’s
Primary port. The result is that Fast Path provides the intelligence for a team to detect, and
proactively react to, network events to maximize the available bandwidth for server data traffic.
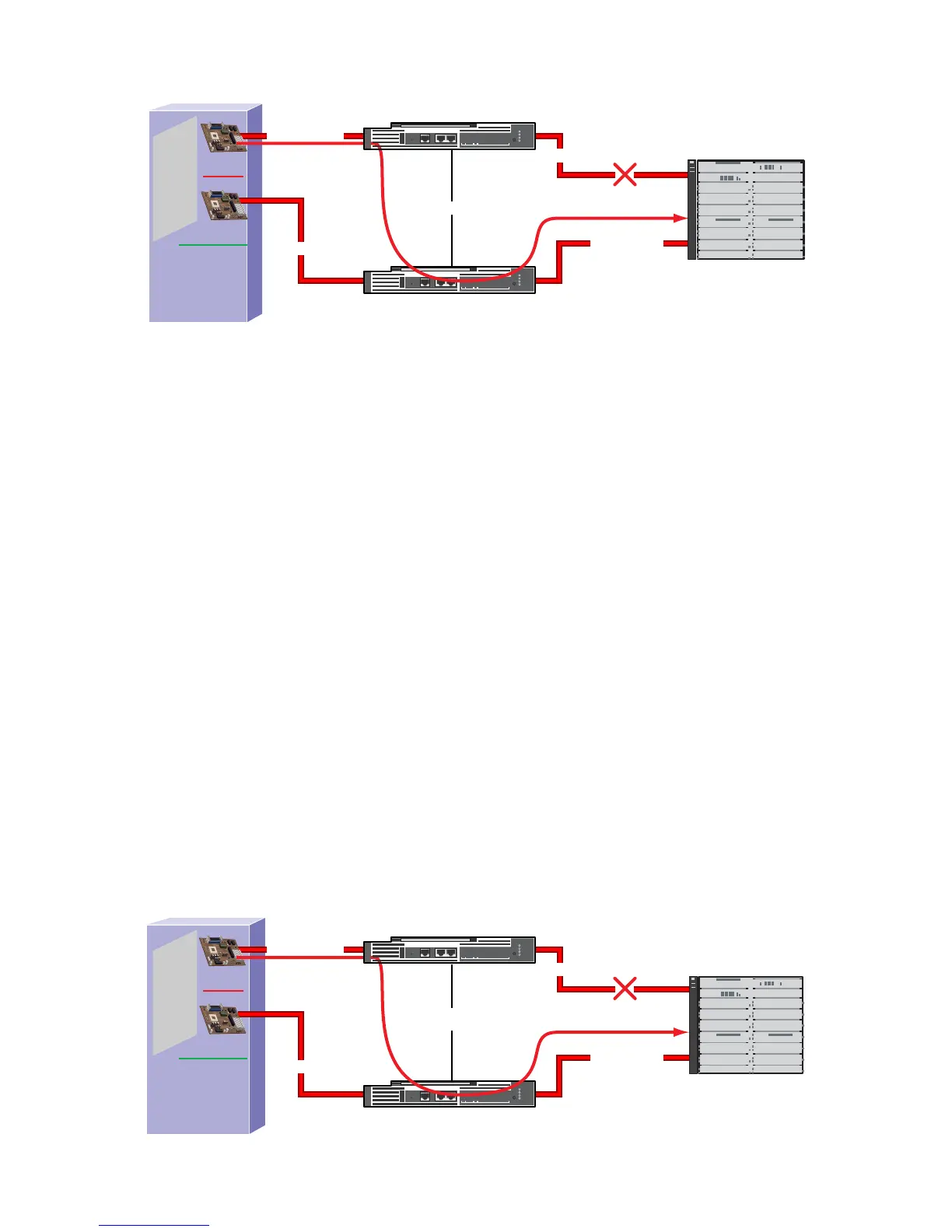
The second example of upstream link failures causing inefficient use of a server’s teamed ports
is found in Figure 4-9. In this example, Switch A has lost direct link with the Core Switch (in
other words, Spanning Tree root switch). Spanning Tree eventually restores connectivity by
unblocking the link between Switch A and Switch B. The link between switch A and Switch B is
also 1000 Mbps link (like the failed link between Switch A and the Core Switch). From a bandwidth
perspective, both Switch A and Switch B still have 1000 Mb access to the core switch. However,
Switch A’s connectivity to the Core Switch is slightly inferior to Switch B’s connectivity because
of hop count (in other words, latency). Since Switch A’s traffic must be transmitted through
Switch B, native Switch A traffic’s hop count and latency to the core segment of the network is
technically worse than native Switch B traffic. As a result, the most efficient use of the server’s
teamed ports is to use the teamed port (in other words, NIC 2) connected to Switch B as the
team’s Primary port instead of the teamed port (in other words, NIC 1) connected to Switch A.
Redundancy mechanisms that only test connectivity (for example, heartbeats, Active Path) will
not detect this problem since connectivity with the core network still exists. A more granular
mechanism needs to be implemented that can not only detect connectivity problems (bad versus
good), but can also detect lower versus higher hop count on a per-teamed port “path-to-core
segment” basis (good versus best).
Figure 4-9 Upstream link failures add extra hop for server receive traffic

 Loading...
Loading...