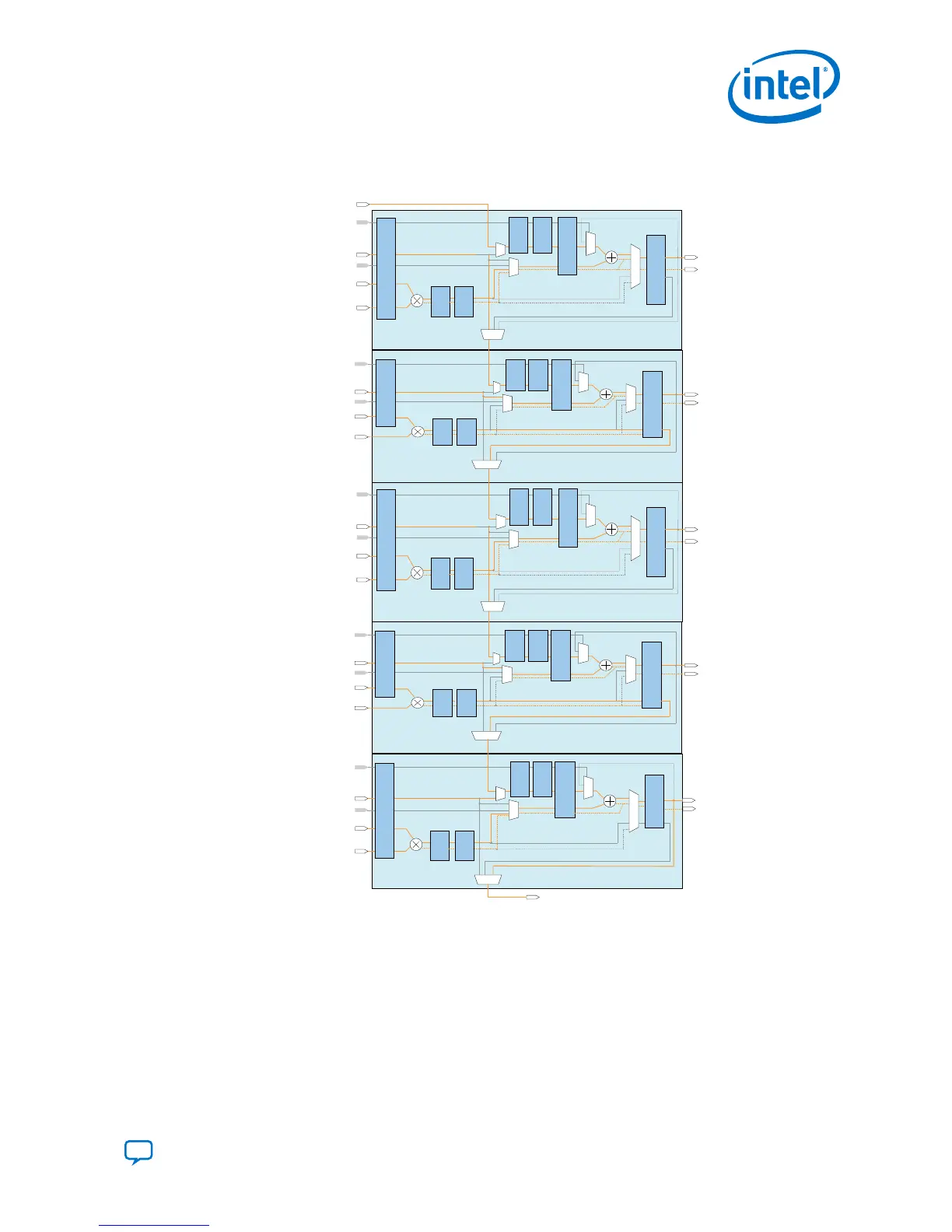
Figure 40. Direct Vector Dot Product Using FP32 Single-Precision Floating-Point
Arithmetic
B
A
AB + CD
AB + CD
D
C
AB + CD + EF + GH
EF + GH
F
E
EF + GH
J
I
IJ +KL
Vector One
*This block diagram shows the functional representation of the DSP block.
The pipeline registers are embedded within the various circuits of the DSP block.
Connect this signal to
the fp32_chainout signal
of the next DSP block in chain.
fp32_chainout[31:0]
fp32_chainin[31:0]
accumulate
fp32_adder_a[31:0]
fp32_mult_a[31:0]
fp32_mult_b[31:0]
Output
Register
Bank
Input
Register
Bank
fp32_result[31:0]
Multiplier
Adder
*Pipeline
Register
Bank
*Pipeline
Register
Bank
*Pipeline
Register
Bank
*Pipeline
Register
Bank
*Pipeline
Register
Bank
fp32_mult_invalid
fp32_mult_inexact
fp32_mult_overflow
fp32_mult_underflow
fp32_adder_invalid
fp32_adder_inexact
fp32_adder_overflow
fp32_adder_underflow
fp32_adder_b[31:0]
AB + CD + EF + GH
H
G
AB + CD +EF + GH + IJ +KL
fp32_chainout[31:0]
fp32_chainin[31:0]
accumulate
fp32_adder_a[31:0]
fp32_mult_a[31:0]
fp32_mult_b[31:0]
fp32_result[31:0]
Multiplier
Adder
*Pipeline
Register
Bank
*Pipeline
Register
Bank
*Pipeline
Register
Bank
*Pipeline
Register
Bank
fp32_mult_invalid
fp32_mult_inexact
fp32_mult_overflow
fp32_mult_underflow
fp32_adder_invalid
fp32_adder_inexact
fp32_adder_overflow
fp32_adder_underflow
Input
Register
Bank
fp32_adder_b[31:0]
Output
Register
Bank
*Pipeline
Register
Bank
Vector Two
Vector One
fp32_chainin[31:0]
accumulate
fp32_adder_a[31:0]
fp32_mult_a[31:0]
fp32_mult_b[31:0]
Output
Register
Bank
Input
Register
Bank
fp32_result[31:0]
Multiplier
Adder
*Pipeline
Register
Bank
*Pipeline
Register
Bank
*Pipeline
Register
Bank
*Pipeline
Register
Bank
*Pipeline
Register
Bank
fp32_mult_invalid
fp32_mult_inexact
fp32_mult_overflow
fp32_mult_underflow
fp32_adder_invalid
fp32_adder_inexact
fp32_adder_overflow
fp32_adder_underflow
fp32_adder_b[31:0]
fp32_chainout[31:0]
fp32_chainin[31:0]
accumulate
fp32_adder_a[31:0]
fp32_mult_a[31:0]
fp32_mult_b[31:0]
fp32_result[31:0]
Multiplier
Adder
*Pipeline
Register
Bank
*Pipeline
Register
Bank
*Pipeline
Register
Bank
*Pipeline
Register
Bank
fp32_mult_invalid
fp32_mult_inexact
fp32_mult_overflow
fp32_mult_underflow
fp32_adder_invalid
fp32_adder_inexact
fp32_adder_overflow
fp32_adder_underflow
Input
Register
Bank
fp32_adder_b[31:0]
Output
Register
Bank
*Pipeline
Register
Bank
Vector Two
fp32_chainout[31:0]
fp32_chainout[31:0]
fp32_chainin[31:0]
accumulate
fp32_adder_a[31:0]
fp32_result[31:0]
Multiplier
Adder
*Pipeline
Register
Bank
*Pipeline
Register
Bank
Register
Bank
*Pipeline
Register
Bank
*Pipeline
Register
Bank
fp32_mult_invalid
fp32_mult_inexact
fp32_mult_overflow
fp32_mult_underflow
fp32_adder_invalid
fp32_adder_inexact
fp32_dder_overflow
fp32_adder_underflow
*Pipeline
Output
Register
Bank
Input
Register
Bank
fp32_adder_b[31:0]
fp32_mult_a[31:0]
fp32_mult_b[31:0]
Multiply Add
IJ +KL + MN + OP
For FP16 half-precision floating-point arithmetic, the direct vector dot product consists
of:
• Sum of two multiplication with FP32 addition mode with chainin feature enabled
• Vector one
• Vector two
3. Intel Agilex Variable Precision DSP Blocks Operational Modes
UG-20213 | 2019.04.02
Send Feedback
Intel
®
Agilex
™
Variable Precision DSP Blocks User Guide
57

 Loading...
Loading...









