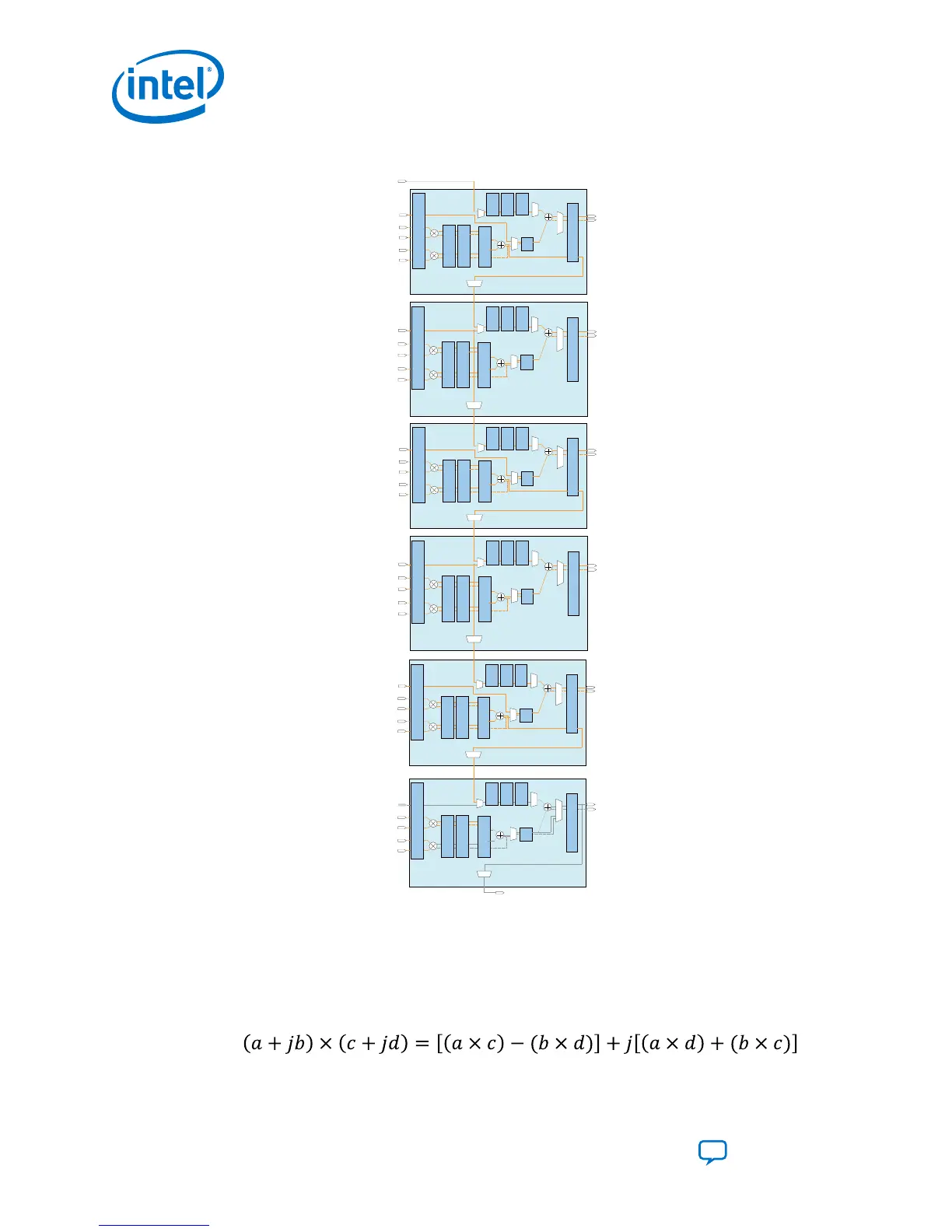
Figure 41. Direct Vector Dot Product Using FP16 Half-Precision Floating-Point Arithmetic
B
A
(A*B) + (C*D)+(E*F)+(H*G)
AB + CD+EF+GH
AB + CD + EF + GH + IJ + KL + MN + OP
F
E
*This block diagram shows the functional representation of the DSP block.
The pipeline registers are embedded within the various circuits of the DSP block.
Vector One
fp32_chainout[31:0]
fp32_chainout[31:0]
fp32_adder_a[31:0]
fp16_mult_top_a[15:0]
fp32_result[31:0]
Input
Register
Bank
Top
Multiplier
Adder
*Pipeline
Register
*Pipeline
Register
*Pipeline
Register
*Pipeline
Register
fp16_mult_top_invalid
fp16_mult_top_underflow
fp16_mult_top_overflow
fp32_adder_invalid
fp32_adder_inexact
fp32_adder_overflow
fp32_adder_underflow
*Pipeline
Register
Output
Register
Bank
fp16_mult_top_b[15:0]
fp16_mult_bot_a[15:0]
Bottom
Multiplier
fp16_mult_bot_b[15:0]
*Pipeline
Register
Register
Adder
fp16_mult_top_inexact
fp16_mult_bot_invalid
fp16_mult_bot_underflow
fp16_mult_bot_overflow
fp16_mult_bot_inexact
fp16_adder_invalid
fp16_adder_inexact
fp16_adder_overflow
fp16_adder_underflow
fp16_mult_top_infinite(extended format)
fp16_mult_top_zero(extended format)
fp16_mult_bot_infinite(extended format)
fp16_mult_bot_zero(extended format)
fp16_adder_infinite(extended format)
fp16_adder_zero(extended format)
C
D
fp32_chainout[31:0]
fp32_chainin[31:0]
fp32_adder_a[31:0]
fp16_mult_top_a[15:0]
fp32_result[31:0]
Input
Register
Bank
Top
Multiplier
Adder
*Pipeline
Register
*Pipeline
Register
*Pipeline
Register
*Pipeline
Register
*Pipeline
Register
Output
Register
Bank
fp16_mult_top_b[15:0]
fp16_mult_bot_a[15:0]
Bottom
Multiplier
fp16_mult_bot_b[15:0]
*Pipeline
Register
Register
Adder
fp16_mult_top_invalid
fp16_mult_top_underflow
fp16_mult_top_overflow
fp32_adder_invalid
fp32_adder_inexact
fp32_adder_overflow
fp32_adder_underflow
fp16_mult_top_inexact
fp16_mult_bot_invalid
fp16_mult_bot_underflow
fp16_mult_bot_overflow
fp16_mult_bot_inexact
fp16_adder_invalid
fp16_adder_inexact
fp16_adder_overflow
fp16_adder_underflow
fp16_mult_top_infinite(extended format)
fp16_mult_top_zero(extended format)
fp16_mult_bot_infinite(extended format)
fp16_mult_bot_zero(extended format)
fp16_adder_infinite(extended format)
fp16_adder_zero(extended format)
fp32_chainin[31:0]
Vector Two
Sum of Two FP16 Multiplication with
FP32 Addition
G
H
fp32_chainout[31:0]
fp32_chainin[31:0]
fp32_adder_a[31:0]
fp16_mult_top_a[15:0]
fp32_result[31:0]
Input
Register
Bank
Top
Multiplier
Adder
*Pipeline
Register
*Pipeline
Register
*Pipeline
Register
*Pipeline
Register
*Pipeline
Register
Output
Register
Bank
fp16_mult_top_b[15:0]
fp16_mult_bot_a[15:0]
Bottom
Multiplier
fp16_mult_bot_b[15:0]
*Pipeline
Register
Register
Adder
fp16_mult_top_invalid
fp16_mult_top_underflow
fp16_mult_top_overflow
fp32_adder_invalid
fp32_adder_inexact
fp32_adder_overflow
fp32_adder_underflow
fp16_mult_top_inexact
fp16_mult_bot_invalid
fp16_mult_bot_underflow
fp16_mult_bot_overflow
fp16_mult_bot_inexact
fp16_adder_invalid
fp16_adder_inexact
fp16_adder_overflow
fp16_adder_underflow
fp16_mult_top_infinite(extended format)
fp16_mult_top_zero(extended format)
fp16_mult_bot_infinite(extended format)
fp16_mult_bot_zero(extended format)
fp16_adder_infinite(extended format)
fp16_adder_zero(extended format)
Vector One
I
J
I
K
L
IJ+KL+MN+OP
IJ+KL+MN+OP
AB + CD + EF + GH + IJ + KL + MN + OP+QR+ST+UV+WX+YZ+ab+cd+ef
Vector One
fp32_chainout[31:0]
fp32_chainout[31:0]
fp32_chainin[31:0]
fp32_adder_a[31:0]
fp16_mult_top_a[15:0]
fp32_result[31:0]
Input
Register
Bank
Top
Multiplier
Adder
*Pipeline
Register
*Pipeline
Register
*Pipeline
Register
*Pipeline
Register
*Pipeline
Register
Output
Register
Bank
fp16_mult_top_b[15:0]
fp16_mult_bot_a[15:0]
Bottom
Multiplier
fp16_mult_bot_b[15:0]
*Pipeline
Register
Register
Adder
fp16_mult_top_invalid
fp16_mult_top_underflow
fp16_mult_top_overflow
fp32_adder_invalid
fp32_adder_inexact
fp32_adder_overflow
fp32_adder_underflow
fp16_mult_top_inexact
fp16_mult_bot_invalid
fp16_mult_bot_underflow
fp16_mult_bot_overflow
fp16_mult_bot_inexact
fp16_adder_invalid
fp16_adder_inexact
fp16_adder_overflow
fp16_adder_underflow
fp16_mult_top_infinite(extended format)
fp16_mult_top_zero(extended format)
fp16_mult_bot_infinite(extended format)
fp16_mult_bot_zero(extended format)
fp16_adder_infinite(extended format)
fp16_adder_zero(extended format)
Vector Two
N
M
O
P
AB + CD+EF+GH+IJ+KL+MN+OP
fp32_chainout[31:0]
fp32_chainin[31:0]
fp32_adder_a[31:0]
fp16_mult_top_a[15:0]
fp32_result[31:0]
Input
Register
Bank
Top
Multiplier
Adder
*Pipeline
Register
*Pipeline
Register
*Pipeline
Register
*Pipeline
Register
*Pipeline
Register
Output
Register
Bank
fp16_mult_top_b[15:0]
fp16_mult_bot_a[15:0]
Bottom
Multiplier
fp16_mult_bot_b[15:0]
*Pipeline
Register
Register
Adder
fp16_mult_top_invalid
fp16_mult_top_underflow
fp16_mult_top_overflow
fp32_adder_invalid
fp32_adder_inexact
fp32_adder_overflow
fp32_adder_underflow
fp16_mult_top_inexact
fp16_mult_bot_invalid
fp16_mult_bot_underflow
fp16_mult_bot_overflow
fp16_mult_bot_inexact
fp16_adder_invalid
fp16_adder_inexact
fp16_adder_overflow
fp16_adder_underflow
fp16_mult_top_infinite(extended format)
fp16_mult_top_zero(extended format)
fp16_mult_bot_infinite(extended format)
fp16_mult_bot_zero(extended format)
fp16_adder_infinite(extended format)
fp16_adder_zero(extended format)
Vector One
QR+ST+UV+WX
I
R
Q
S
T
QR+ST+UV+WX+YZ+ab+cd+efQR+ST+UV+WX+YZ+ab+cd+ef
Vector One
fp32_chainout[31:0]
fp32_chainout[31:0]
fp32_chainin[31:0]
fp32_adder_a[31:0]
fp16_mult_top_a[15:0]
fp32_result[31:0]
Input
Register
Bank
Top
Multiplier
Adder
*Pipeline
Register
*Pipeline
Register
*Pipeline
Register
*Pipeline
Register
*Pipeline
Register
Output
Register
Bank
fp16_mult_top_b[15:0]
fp16_mult_bot_a[15:0]
Bottom
Multiplier
fp16_mult_bot_b[15:0]
*Pipeline
Register
Register
Adder
fp16_mult_top_invalid
fp16_mult_top_underflow
fp16_mult_top_overflow
fp32_adder_invalid
fp32_adder_inexact
fp32_adder_overflow
fp32_adder_underflow
fp16_mult_top_inexact
fp16_mult_bot_invalid
fp16_mult_bot_underflow
fp16_mult_bot_overflow
fp16_mult_bot_inexact
fp16_adder_invalid
fp16_adder_inexact
fp16_adder_overflow
fp16_adder_underflow
fp16_mult_top_infinite(extended format)
fp16_mult_top_zero(extended format)
fp16_mult_bot_infinite(extended format)
fp16_mult_bot_zero(extended format)
fp16_adder_infinite(extended format)
fp16_adder_zero(extended format)
Vector Two
V
U
W
X
Connect this signal to
the fp32_chainout signal
of the next DSP in the chain
Connect this signal to
the fp32_result signal
of the next DSP in the chain
3.2.3.3. Complex Multiplication
The Intel Agilex devices support the floating-point arithmetic single precision complex
multiplier using four Intel Agilex variable-precision DSP blocks.
Figure 42.
3. Intel Agilex Variable Precision DSP Blocks Operational Modes

 Loading...
Loading...









