THE ‘UNVOICED’ SECTION
Unvoiced sounds (fricative/sibilants) are common in
human languages and can be found in words containing
or starting with s, f, z, ch and other fricative sounds ([s]
[z] [ʃ] [tʃ] [dʒ] [ts] [ʂ] [f] [v] [ɸ] [θ] [ʒ] etc.).
Historically, all vocoders have an additional section to
manage these kinds of sounds. Usually that section
worked with a sort of “unvoiced detection circuit”: you
can get an approximated idea of it imagining a “de-es-
ser”, which detects the presence of certain frequencies in
the sound spectrum, and instead of doing a selective band
compression attenuating that frequencies, it controls a
sort of mixer that changes the input of the filter from the
main to a noise signal, and is capable of very fast transi-
ents.
The FUMANA has been designed to be a spectral edit-
ing tool, more than a vocoder: for this reason, since its
sketches shared a lot of things with vocoding circuits, we
developed our own approach of the Unvoiced section,
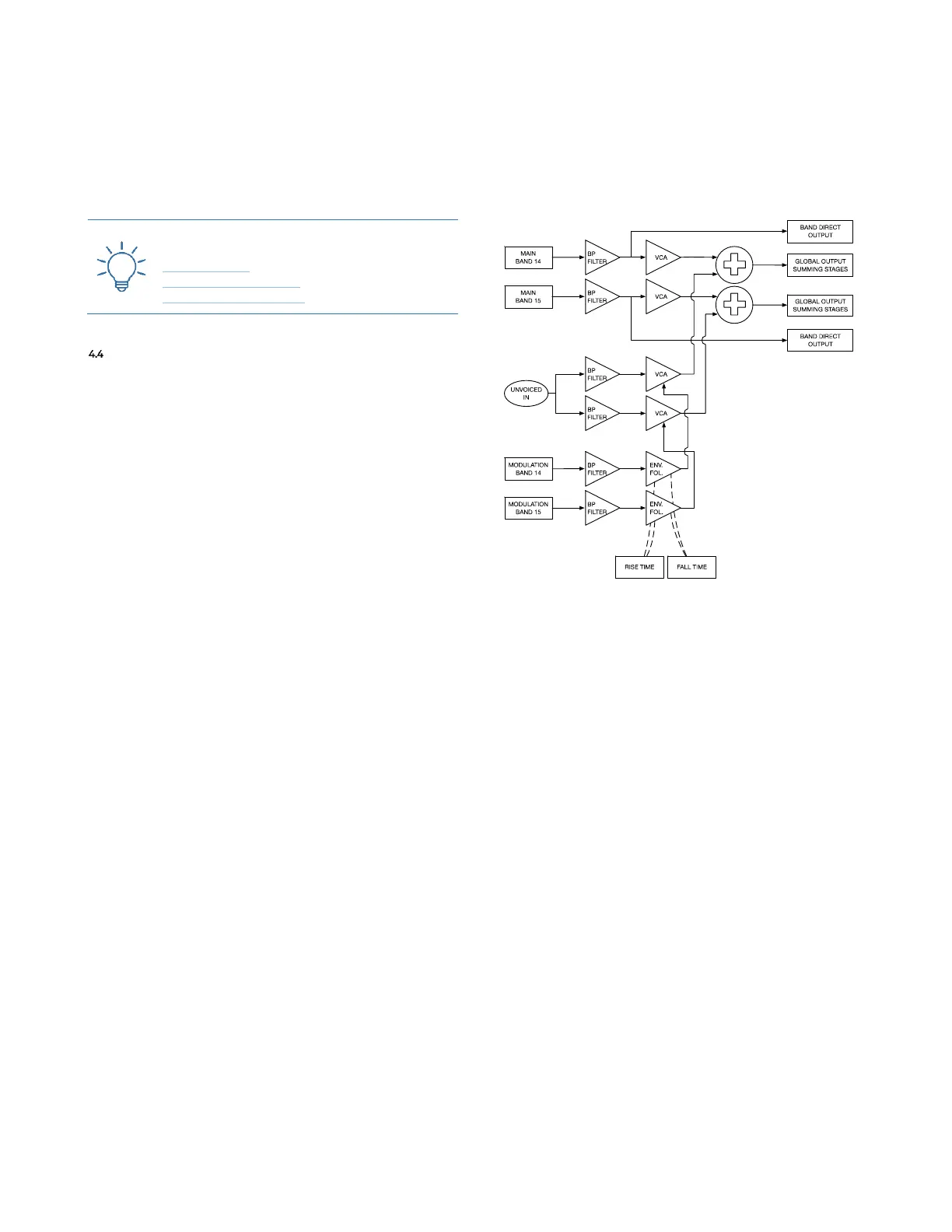
which for sure leads to different results. It works manag-
ing the amplitude of the noise and summing the result
with the main signal on 2 selected bands, instead of vary-
ing the mix between main and noise signal. The two se-
lected bands are the 14 and 15. The jack socket in the
Unvoiced area is the input (A.9) for the noise audio signal,
that may be provided by the SAPÈL (we tend to suggest
pink noise or white noise). The potentiometer (A.10) sets
the noise level.
It is also important to specify that even if the input is
one (mono), the detector and the amplitude manager of
that noise is dual and totally independent. Band 14 has
its own envelope follower signal controlling its own VCA,
as well as band 15. This means that when used with two
different modulation signals and two outputs (odd and
even), the result of the unvoiced signal added to the main
one is totally independent.
Also, we worked on the way these envelopes are
achieved: in the FUMANA they tend to be much “softer”
than normal to reduce risks of “envelopes bounces” re-
sulting in really fast “noise sparks”. This approach allows
to use the unvoiced section also for non-vocal purposes.
A good example is using drums with cymbals/hats as
modulation source: in this case, the unvoiced sections
helps to detect when there is material and recreate cym-
bals or snare wires. Anyway, this does not limit you to put
any kind of waveform in the unvoiced input and start to
experiment by yourself.
Figure 20: FUMANA’s Unvoiced section.
5 FILTER DESIGN
Each of the two filter arrays is based on 16 parallel an-
alog bandpass filters. The main filter bands from 2 to 15
are mainly based on Bessel calculation, while bands 1 and
16 are respectively a lowpass and highpass filter with a
custom method to obtain better musical results. All bands
on the main filter array use an 8th order slope (48dB/oct).
Conversely, the modulation filter array uses a 6th order
filter slope (36dB/oct), and an additional stage to com-
pensate each band’s energy. The calculation method
used was optimized for this specific purpose.
The crossover frequency between each filter from band
2 to 15 is an approximation of an interval of ~5.5 semi-
tones (or 11/24 of an octave). This results in a distance
between odd bands (and also between each even band) of
~11 semitones (11/12 of an octave), or a Major 7th. The
ratio is defined in order to limit the chance to obtain a
recursive tone emphasis/attenuation over the whole au-
dio spectrum.
The first and last band’s frequencies are calculated in
order to achieve the best regulation of “sub-bass” and
“upper-end”.
The filters are designed to guarantee the flattest fre-
quency response on the ALL output, which within
±1.5dB from band 2 to 15, and globally between ±4.5dB.