6. Redundancy with NX3030 CPU
298
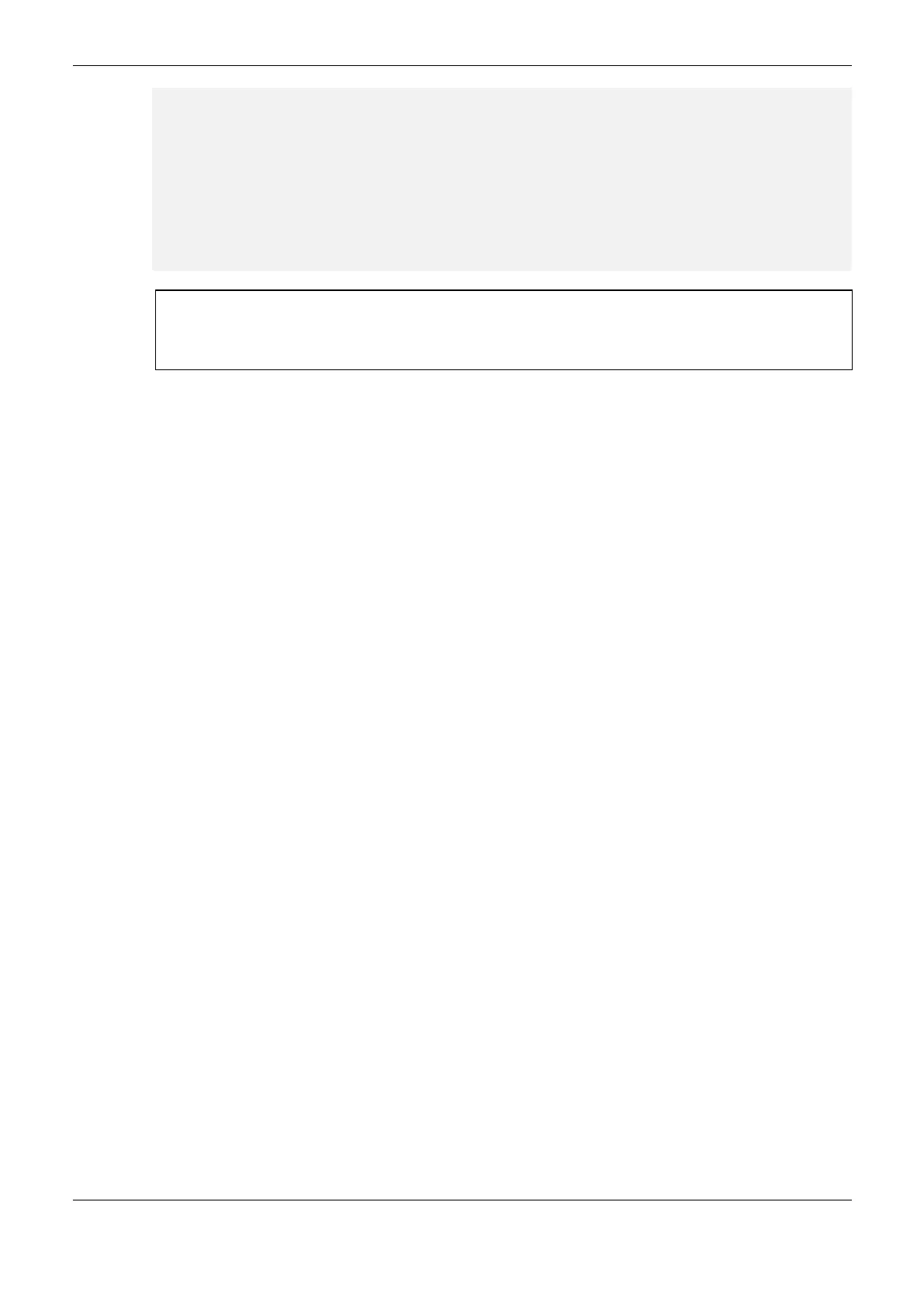
IF (DG_NX3030.tDetailed.Ethernet.NET1.bLinkDown AND
DG_NX3030.tDetailed.Ethernet.NET2.bLinkDown) THEN
//Change the local PLC to StandBy.
DG_NX4010.tRedundancy.RedCmdLoc.bStandbyLocal := TRUE;
END_IF
ELSE
//NIC Teaming disabled: error in one of NETs to execute a switchover.
IF (DG_NX3030.tDetailed.Ethernet.NET1.bLinkDown OR
DG_NX3030.tDetailed.Ethernet.NET2.bLinkDown) THEN
//Change the local PLC to StandBy.
DG_NX4010.tRedundancy.RedCmdLoc.bStandbyLocal := TRUE;
END_IF
END_IF
ATTENTION:
When two Ethernet interfaces form a NIC Teaming pair, the inactive interface will always have the
IP address 0.0.0.0. This isn’t a valid IP and is no possible to configure manually an interface with
this address.
Fault Tolerance
The main objective of a redundant CPU is the system availability increase. The availability is the
ratio between the time while the system is working properly and the total time since the system has
been implemented. For instance, if a system was implemented 10 years ago and during this time,
wasn’t working due to failures for a year, then its availability was only 90%. This kind of availability
is usually unacceptable for critic systems, where 99.99% availability is required, or even more.
In order to reach this availability level, several strategies are necessary:
Utilization of more reliable components (with high MTBF or Mean Time between Failures),
contributing for the MTBF increase of the system as a whole
Utilization of redundancy for, at least, the most critical components or components with smaller
MTBF, in such a way that a component failure can be tolerated without stopping the system. If
the redundancy is implemented through components duplication, it will be necessary that both
fail for the system as a whole become unavailable
High diagnostics coverage, especially in redundant components. The component redundancy
isn’t very useful for the availability increase when is not possible to discover which component
failed. In this case, the first failure in one component still doesn’t drop the system, but remains
hidden, until the second failure occurs, dropping the system, as the first failure wasn’t yet
repaired. The failures can be classified between diagnosable and hidden. It’s strongly
recommended that all redundant components failures are diagnosable
It’s also important that non-redundant components have wide diagnostics coverage, as,
frequently, the system can continue working even with a non-redundant component failure. The
component may not being requested, e.g. a relay with NO contact which rarely has its coil
activated, doesn’t have its failure detected until the moment the system requires its closing
Low repair time for non-redundant components. A non-redundant component failure can drop the
system, and during the repair, the system will be unavailable
Possibility of repairing or substituting a redundant component without stopping the system. If
this possibility exists, a great availability increase it got. Otherwise, a stop must be programmed
in order to substitute the component and the repair time is computed as unavailable time
Low repair time for redundant components. A redundant component failure doesn’t drop the
system, but during its repair, a failure in its redundant pair could happen. For this reason, it’s
important that the failure is repaired quickly after diagnosed. The higher the repair time, the
higher the probability of a second failure to occur in the redundant component during this time,
what would drop the system. Therefore, the higher the repair time, the lower the system
availability
Program periodic of-line tests in components in order to detect not automatically diagnosable
failures by the system. The objective is to detect hidden failures, especially in redundant
components or simple components which aren’t being requested (e.g. a security relay). Off-line
tests, sometimes, imply in system stopping what decreases the availability. Normally, special
 Loading...
Loading...