No particular typeface is assumed for any particular code page. The typeface is defined as a font by the
assignment of size, weight, and posture.
Character IDs and Code Points
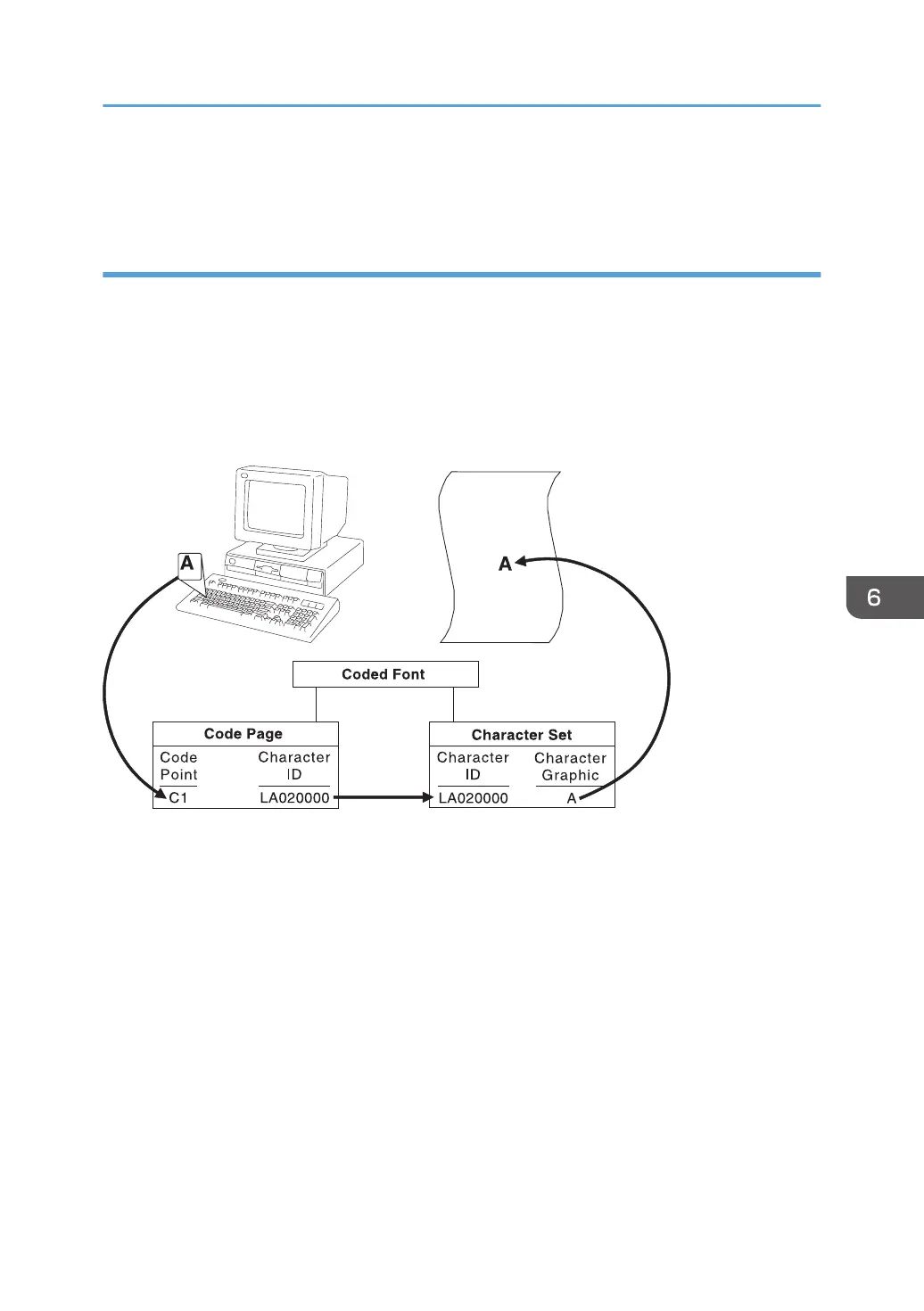
In IBM font structure, a code page maps each character of text to the characters in a character set. The
following figure shows how a code page maps text to the characters in a character set. As you enter
your text at a computer terminal, each keyboard character is translated into a code point. When the text
is printed, each code point is matched to a character ID on the code page you specified. The character
ID then is matched to the image (raster pattern) of the character in the character set you specified. The
image in the character set is the image that is printed in your text. To be a valid code page for a
particular character set, all character IDs in the code page must be included in that character set.
Every code page has 256 positions, or code points, that represent potential characters. Each of the
code points is normally identified by its bit configuration in hexadecimal, with two hex characters per
byte. The range of values is hex 00 through hex FF, or 256 values. The code page determines which
character prints for each of the printable code points.
A character ID is an 8-byte standard identifier for a character regardless of its type family. For example,
all uppercase "A" have the same character ID (LA020000). Character IDs also are called graphic
character identifiers (GCIDs).
Binary: 11000001
Decimal: 193
Hexadecimal: C1
The following figure shows an example of a part of a code page. When the printer receives
hexadecimal code point C1 for the code page shown (code page 00037 Version 1), it prints an
uppercase A (character ID LA020000). Baselines for each character on the example code page show
the general alignment of characters.
IBM Font Structure
91
 Loading...
Loading...





