478 Implementing the IBM Storwize V5000 Gen2 with IBM Spectrum Virtualize V8.1
Predecide mechanism
Some data chunks have a higher compression ratio than others. Compressing some of the
chunks saves little space, but still requires resources, such as processor (CPU) and memory.
To avoid spending resources on incompressible data, and to provide the ability to use a
different, more effective compression algorithm.
The chunks that are below a given compression ratio are skipped by the compression engine,
saving CPU time and memory processing. Chunks that are not compressed with the main
compression algorithm, but that still can be compressed well with the other, are marked and
processed accordingly. The result might vary because predecide does not check the entire
block, only a sample of it.
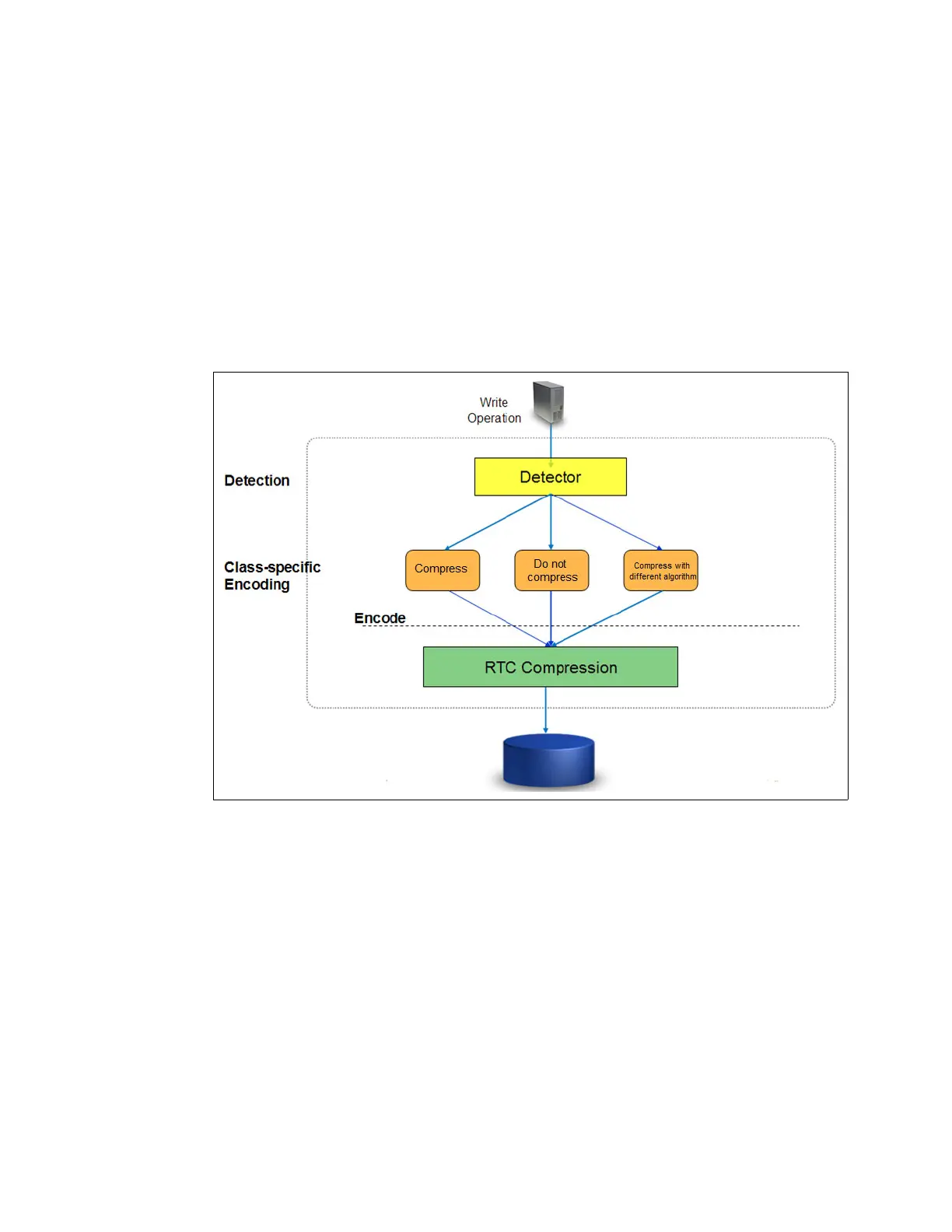
Figure 9-29 shows how the detection mechanism works.
Figure 9-29 Detection mechanism
Temporal compression
RACE offers a technology leap beyond location-based compression, called temporal
compression
. When host writes arrive to RACE, they are compressed and fill up fixed size
chunks, also named as
compressed blocks. Multiple compressed writes can be aggregated
into a single compressed block. A dictionary of the detected repetitions is stored within the
compressed block.
When applications write new data or update existing data, it is typically sent from the host to
the storage system as a series of writes. Because these writes are likely to originate from the
same application and be of the same data type, more repetitions are usually detected by the
compression algorithm. This type of data compression is called
temporal compression
because the data repetition detection is based on the time the data was written into the same
compressed block.
 Loading...
Loading...









