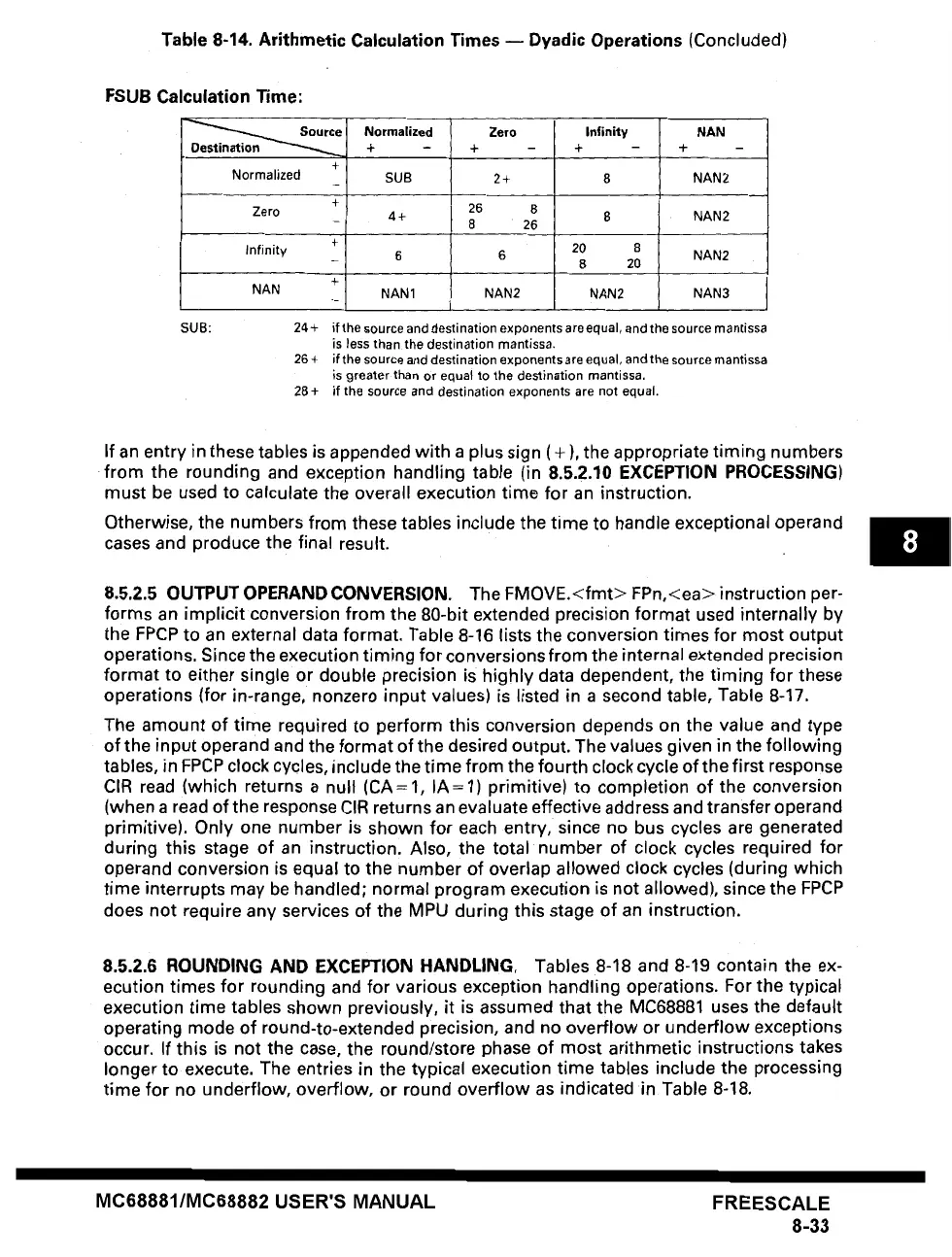
Table 8-14. Arithmetic Calculation Times m Dyadic Operations
(Concluded)
FSUB Calculation Time:
_ _~~ Source
Destination
+
Normalized
+
Zero
+
Infinity
Normalized Zero NAN
+ - + + -
SUB 2+ NAN2
4+ 26 8 NAN2
8 26
6 6 NAN2
Infinity
- + -
8
8
20 8
8 20
NAN2
+
NAN NAN1 NAN2 NAN3
SUB: 24+ if the source and destination exponents are equal, and the source mantissa
is Jess than the destination mantissa.
26 + if the source and destination exponents are equal, and the source mantissa
is greater than or equal to the destination mantissa.
28 + if the source and destination exponents are not equal.
If an entry in these tables is appended with a plus sign ( + ), the appropriate timing numbers
from the rounding and exception handling table (in 8.5.2.10 EXCEPTION PROCESSING)
must be used to calculate the overall execution time for an instruction.
Otherwise, the numbers from these tables include the time to handle exceptional operand
cases and produce the final result.
8.5.2.5 OUTPUT OPERAND CONVERSION. The FMOVE.<fmt> FPn,<ea> instruction per-
forms an implicit conversion from the 80-bit extended precision format used internally by
the FPCP to an external data format. Table 8-16 lists the conversion times for most output
operations. Since the execution timing for conversions from the internal
extended
precision
format to either single or double precision is highly data dependent, the timing for these
operations (for in-range, nonzero input values) is listed in a second table, Table 8-17.
The amount of time required to perform this conversion depends on the value and type
of the input operand and the format of the desired output. The values given in the following
tables, in FPCP clock cycles, include the time from the fourth clock cycle of the first response
CIR read (which returns a null (CA=l, IA=l) primitive) to completion of the conversion
(when a read of the response CIR returns an evaluate effective address and transfer operand
primitive). Only one number is shown for each entry, since no bus cycles are generated
during this stage of an instruction. Also, the total number of clock cycles required for
operand conversion is equal to the number of overlap allowed clock cycles (during which
time interrupts may be handled; normal program execution is not allowed), since the FPCP
does not require any services of the MPU during this stage of an instruction.
8.5.2.6 ROUNDING AND EXCEPTION HANDLING.
Tables 8-18 and 8-19 contain the ex-
ecution times for rounding and for various exception handling operations. For the typical
execution time tables shown previously, it is assumed that the MC68881 uses the default
operating mode of round-to-extended precision, and no overflow or underflow exceptions
occur. If this is not the case, the round/store phase of most arithmetic instructions takes
longer to execute. The entries in the typical execution time tables include the processing
time for no underflow, overflow, or round overflow as indicated in Table 8-18.
MC68881/MC68882 USER'S MANUAL
FREESCALE
8-33